")


































تحميل برنامج Aquaforest Kingfisher | لتحليل وتحرير ملفات PDF
برنامج Aquaforest Kingfisher ليس مجرد محلل ملفات PDF، بل هو مساعد ذكي لتحسين كفاءة الفهرسة وضمان قابلية البحث في المستندات. سواء كنت تعمل في الأرشفة الرقمية أو إدارة الوثائق أو التحليل القانوني، فإن Kingfisher يمنحك أداءً احترافيًا يختصر الوقت ويرفع الإنتاجية.
ما هو برنامج Aquaforest Kingfisher ولماذا يعد أداة لا غنى عنها للمؤسسات؟
برنامج Aquaforest Kingfisher هو أداة احترافية لاستخراج البيانات من ملفات PDF وفحصها وتقسيمها وإعادة تسميتها اعتمادًا على النص أو الباركود داخل الصفحات، مع دعم OCR لتحويل ملفات PDF المصورة إلى نص قابل للمعالجة والبحث. يمكّن المؤسسات من تحويل المحتوى المحبوس داخل فواتير وتقارير عملاء وسجلات ممسوحة إلى CSV أو Excel أو نص، مع تشغيل مستقل على خوادم ويندوز وتكامل عملي مع بيئات SharePoint وسير عمل الترحيل.
لماذا هو ضروري للمؤسسات؟
-
يعالج أحجامًا ضخمة من ملفات PDF دفعة واحدة، مع مهام ذكية مثل الاستخراج، التقسيم، وإعادة التسمية المبنية على محتوى الصفحة أو الباركود، ما يختصر وقت الأرشفة والفهرسة بشكل ملحوظ.
-
يحوّل المستندات المصورة إلى بيانات منظمة قابلة للبحث والتحليل عبر OCR، ويصدرها لملفات CSV/Excel لسهولة الدمج مع الأنظمة المؤسسية وتقارير الجودة.
-
يعمل كحل مستقل قابل للنشر على خوادم ويندوز مع دعم بيئات SharePoint وملفات النظام، ما يسهّل المعالجة المسبقة قبل ترحيلات المحتوى واسعة النطاق.
القدرات الأساسية
-
استخراج البيانات والجداول والنصوص إلى CSV وTXT وExcel مع التعرف على الجداول وتقليل التدخل اليدوي في حالات كثيرة.
-
تقسيم الملفات، استخراج الصفحات، وإعادة تسمية المستندات بناءً على مناطق نص محددة أو رموز شريطية عند إحداثيات داخل الصفحة، مع واجهة رسومية وسطر أوامر.
-
إعداد سمات PDF مثل الأمان والبيانات الوصفية ضمن نفس سير العمل لتوحيد معايير الأرشفة.
حالات الاستخدام العملية
-
تدقيق جودة الأرشيف والتحقق من قابلية البحث قبل تحميل الملفات إلى SharePoint أو أنظمة إدارة المستندات.
-
أتمتة معالجة الفواتير وكشوف الحساب والتقارير عبر تقسيم وإعادة تسمية المستندات حسب محتواها أو باركودها وربطها بأنظمة ERP/CRM.
-
استخراج دفعي للبيانات من ملايين الصفحات لإعداد تقارير الامتثال والتحليلات المالية بسرعة وموثوقية.
التكامل وسير العمل
-
يتكامل بسهولة مع منصات الأتمتة مثل Autobahn DX عبر خطوات معالجة تسمح بالمجلدات المرصودة والمهام المجدولة دون الحاجة لبرمجة مخصصة.
-
يدعم التشغيل في بيئات افتراضية وخيارات تركيب عن بُعد بواسطة مهندسين مختصين مع صيانة ضمن الاشتراك، ما يسرّع الإطلاق المؤسسي.
متطلبات النظام
-
أنظمة مدعومة: Windows 10/11 وWindows Server 2012 R2/2016/2019/2022 مع .NET Framework 4.7.2 وما بعده بحسب الإصدار.
-
موارد موصى بها: من i5 و8 جيجابايت RAM لرخصة نواة واحدة وحتى مواصفات أعلى للتوازي متعدد الأنوية، مع مساحة قرص تقارب 450 ميجابايت للإصدار الأحدث.
قيمة العمل والعائد
-
تخفيض التكاليف الناتجة عن الإدخال اليدوي عبر استخراج تلقائي دقيق من PDF وتحويله إلى بنى بيانات قياسية قابلة للدمج.
-
تسريع ترحيل المحتوى وضمان الجودة النصية قبل الفهرسة، ما يحسّن قابلية الاكتشاف والامتثال عبر المستودعات المؤسسية.
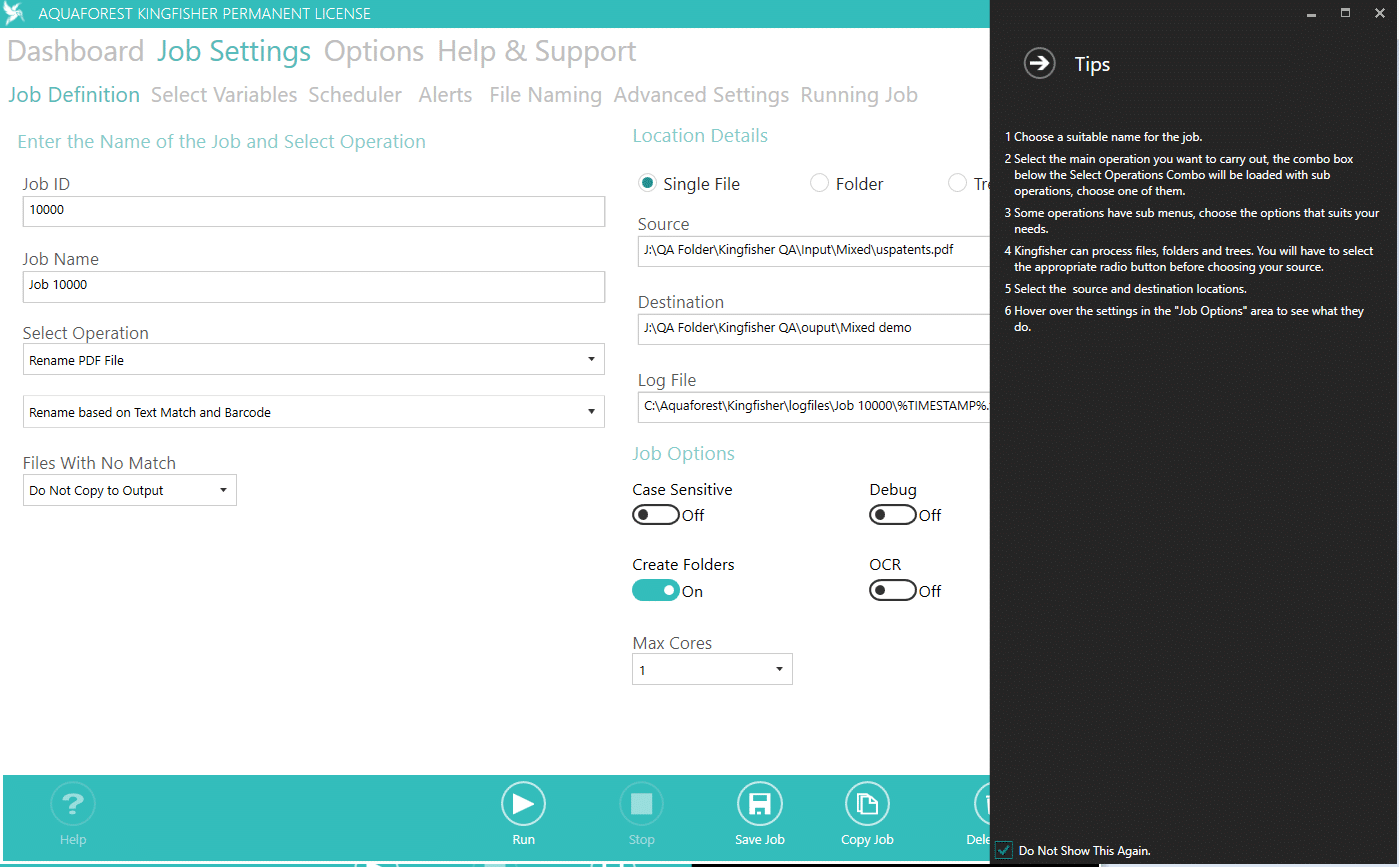
التعريف الكامل بقدرات Kingfisher في تحليل ملفات PDF بدقة عالية
Aquaforest Kingfisher يقدم حزمة قدرات متخصصة لتحليل ملفات PDF بدقة عالية عبر استخراج المحتوى، التقسيم، وإعادة التسمية اعتمادًا على النص أو الباركود مع دعم OCR، وإخراج النتائج إلى CSV/Excel ونصوص قياسية لمعالجة مؤسسية واسعة النطاق.
استخراج المحتوى الذكي
-
-
-
استخراج النصوص والبيانات من PDF إلى CSV وTXT وExcel مع التعرف التلقائي على الجداول وتقليل التدخل اليدوي في حالات كثيرة لتحويل المستندات إلى بيانات قابلة للتحليل مباشرة.
-
يدعم استخراج مناطق محددة داخل الصفحة عبر Zonal Patterns لتحديد الحقول الحساسة مثل أرقام الفواتير وتواريخ المستندات دون الحاجة لمعالجة الملف بالكامل.
-
-
التعرف الضوئي على الحروف OCR
-
-
-
يقرأ النص داخل ملفات PDF المصورة ويحولها إلى نصوص قابلة للبحث والاستخراج، ما يمكّن من تطبيق القواعد القائمة على النص حتى عندما تكون الصفحات صورًا فقط.
-
يدمج القيم المستخرجة عبر OCR ضمن قواعد التسمية والتقسيم وإخراج الجداول، ما يضمن تناسق النتائج عبر مجموعات مستندات مختلطة الجودة.
-
-
التقسيم وإعادة التسمية حسب المحتوى
-
-
-
تقسيم ملفات PDF تلقائيًا بناءً على أنماط نصية أو باركودات محددة داخل الصفحة، بما يشمل فصل الدُفعات، الفواتير، وكشوف الحساب إلى مستندات فردية بدقة.
-
إعادة تسمية الملفات ديناميكيًا باستخدام متغيرات مرنة مثل قيم النص/الباركود، فهارس التقسيم، أرقام الصفحات، الإشارات المرجعية، والطابع الزمني لبدء المهمة.
-
-
تعريف المناطق والإحداثيات
-
-
-
تعيين مناطق استخراج دقيقة على الصفحة عبر Zone Definer لاختيار نص أو باركود عند إحداثيات محددة، بما في ذلك قواعد مثل “النص بعد القيمة” لالتقاط الحقول تابعة لعناوين ثابتة.
-
يدعم التقاط قيم متعددة وتعيينها إلى متغيرات قابلة لإعادة الاستخدام في قوالب أسماء الملفات أو حقول الإخراج، ما يضمن اتساق التسمية والفرز.
-
-
التعرف على الباركود
-
-
-
فصل المستندات واستخراج الصفحات وإعادة التسمية اعتمادًا على باركودات محددة أو ضمن منطقة معرفة، مع تصحيحات حديثة لضمان كتابة القيم بدقة في CSV/XLSX.
-
الجمع بين النص والباركود في نفس سير العمل لتعزيز الاعتمادية عند اختلاف جودة الطباعة أو المسح.
-
-
إخراج وتحويل البيانات
-
-
-
تصدير النتائج بصيغ CSV وTXT وXLSX لتسهيل الدمج مع أنظمة ERP/CRM ومستودعات البيانات، مع خيارات تسمية ملفات وإخراج منظمة.
-
إعداد السمات والبيانات الوصفية والأمان داخل PDF ضمن نفس المهمة لتوحيد معايير الأرشفة بعد الاستخراج أو التقسيم.
-
-
واجهات التشغيل والأتمتة
-
-
-
واجهة رسومية سهلة وسطر أوامر لاستخدامات الدُفعات والدمج مع سكربتات مؤسسية، ما يلائم فرق التشغيل والبنية التحتية.
-
تكامل سلس مع منصات الأتمتة مثل Autobahn DX عبر مجلدات مراقبة ومهام مجدولة وسير عمل خالٍ من التعليمات البرمجية لمعامل المعالجة الضخمة.
-
-
الأداء والتوازي
-
-
-
خيارات متعددة الأنوية لمعالجة أحجام كبيرة بسرعة، مع تدرج من نواة واحدة حتى ثماني أنوية وفق الترخيص، ما يقلل زمن النوافذ التشغيلية.
-
دعم البيئات الافتراضية والنشر على خوادم ويندوز الحديثة لضمان الاعتمادية وتوزيع العبء في مراكز البيانات المؤسسية.
-
-
حالات استخدام دقيقة
-
-
-
معالجة دفعات الفواتير وتقارير البنوك عبر تقسيم المستندات وإعادة تسميتها وفق رقم المستند أو باركوده وربطها بملفات CSV للترحيل.
-
استخراج جداول من تقارير دورية إلى Excel مع الحفاظ على البنية، ما يسرّع التحليلات والامتثال والرقابة الداخلية.
-
-
قيمة الدقة للمؤسسات
-
-
تخفيض الأخطاء البشرية عبر قواعد محتوى قابلة للتكرار ومناطق محددة، ما يحسن الجودة ويقلل الحاجة للمراجعات اليدوية.
- رفع قابلية البحث والاكتشاف في أرشيفات PDF وتمكين التحليلات التشغيلية السريعة، مع بنية تناسب عمليات الترحيل والفهرسة على نطاق واسع.
-
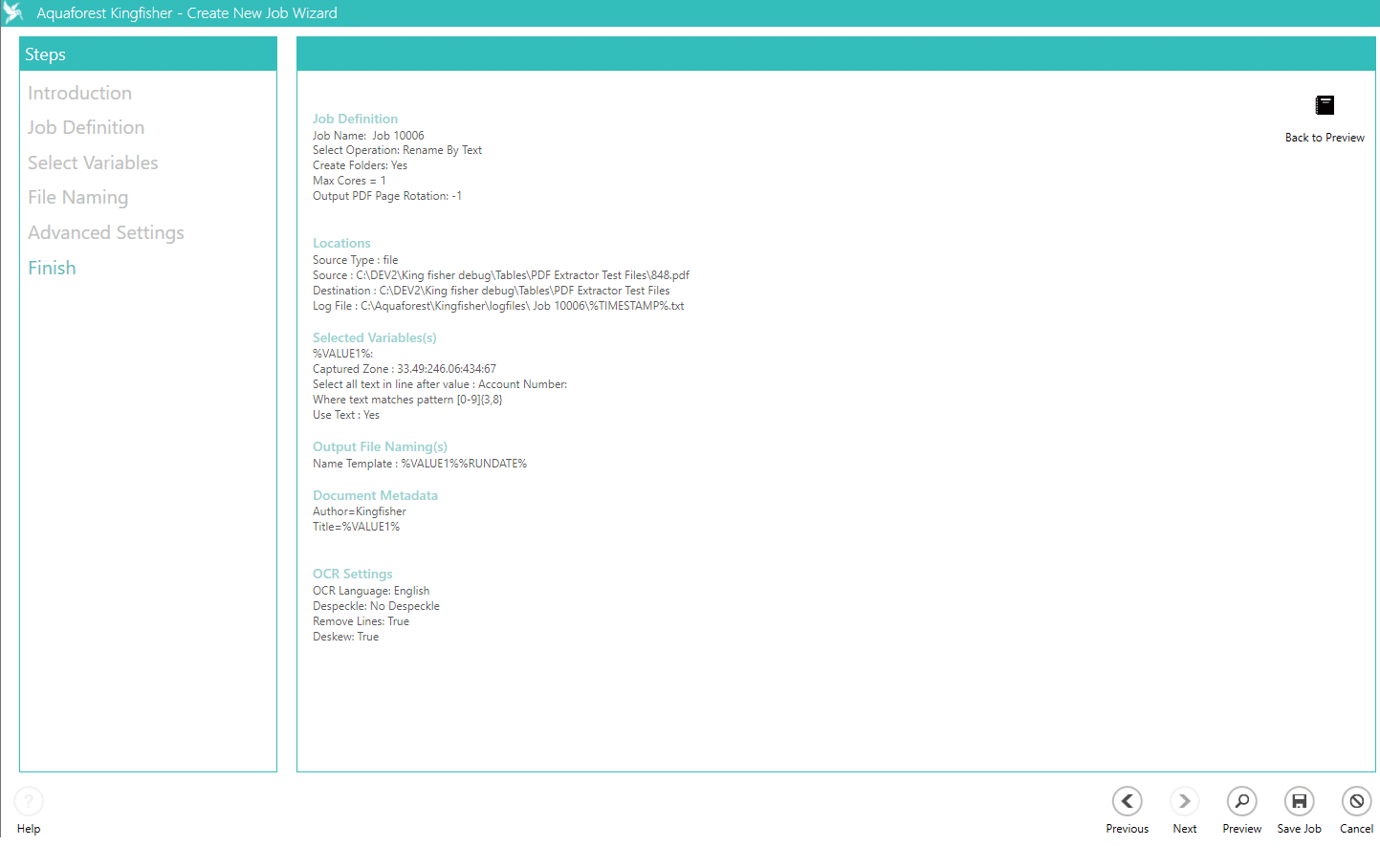
مزايا برنامج Aquaforest Kingfisher في المعالجة الجماعية للمستندات
يوفر Aquaforest Kingfisher مزايا قوية للمعالجة الجماعية تجعل التعامل مع آلاف ملفات PDF سريعًا ومستقرًا وقابلًا للأتمتة في البيئات المؤسسية واسعة النطاق.
معالجة متوازية متعددة الأنوية
-
يسمح بتحديد عدد الأنوية المستخدمة لكل مهمة عبر خيار Max Cores لمعالجة عدة ملفات بالتوازي، وهي ميزة متاحة في ترخيص الخادم لرفع الإنتاجية وتقليل زمن الدُفعات الكبيرة.
-
التوازي يحسن استغلال موارد الخادم في ساعات التشغيل المحدودة، ويدعم سيناريوهات المعالجة الليلية أو ضمن نوافذ الصيانة بسهولة.
أوتمتة كاملة عبر الواجهة الرسومية وسطر الأوامر
-
يوفر واجهة مرئية لتكوين مهام استخراج/تقسيم/إعادة تسمية بالإضافة إلى تشغيل عبر سطر الأوامر لدمجه في سكربتات وجدولة المهام المؤسسية دون تدخل يدوي.
-
يمكن حفظ ملفات تعريف المهام وتشغيلها دوريًا مع نفس الإعدادات لضمان الاتساق عبر الدُفعات وتبسيط صيانة خطوط المعالجة.
استخراج بيانات وجداول على نطاق واسع
-
ينجز استخراج الجداول إلى CSV أو XLSX مع خيارات متقدمة مثل الإلحاق بملف موجود أو إضافة ورقة عمل لكل ملف PDF، ما يبسط تجميع النتائج لآلاف المستندات في مخرجات موحدة.
-
يتيح التعرف الجدولي شبه التلقائي تقليل التدخل اليدوي في ضبط حدود الجداول، وهو أمر حاسم عند معالجة أرشيفات ضخمة متنوعة التنسيق.
تقسيم وإعادة تسمية جماعي بالاعتماد على المحتوى والباركود
-
يدعم تقسيم المستندات على مستوى الدُفعات وفق أنماط نصية أو باركود محدد، مع تحسينات بارزة في محرك الباركود لرفع الدقة والاستقرار في الإصدارات الحديثة.
-
قوالب التسمية الديناميكية تمكّن من إنتاج ملفات مرتبة تلقائيًا باستخدام قيم مستخرجة مثل رقم الفاتورة أو التاريخ أو الفهرس، ما يختصر وقت الأرشفة إلى حد كبير.
دمج OCR في مهام الدُفعات
-
خيار OCR يتيح معالجة ملفات PDF المصورة ضمن نفس خط المهام الجماعي لتحويلها إلى نص قابل للبحث والاستخراج دون فصل سير العمل.
-
تحديث محرك OCR في الإصدار 2.5 عبر Aquaforest SDK 3 حسن الأداء والدقة، ما يضمن جودة أعلى عند معالجة مجموعات كبيرة مختلطة الجودة.
تكامل مؤسسي وسير عمل مراقَب
-
يتكامل مع منصات الأتمتة مثل Autobahn DX لتشغيل مهام بدون كود عبر مجلدات مراقبة وجدولة مرنة، ما يوفّر مسارًا صناعيًا لمعالجة جماعية مستمرة.
-
دعم المصادقة الحديثة OAuth2 لـ SharePoint Online والبريد يسهل الدمج الآمن في بيئات Microsoft 365 لمعالجة واستلام وإخراج الملفات على نطاق واسع.
موثوقية وتشخيص في بيئات الإنتاج
-
سجلات تفصيلية وخيار Debug للمساعدة في تتبع الأعطال الفردية ضمن الدُفعات الكبيرة دون إيقاف كامل المهمة، مع الحفاظ على ملفات مؤقتة للتحليل عند الحاجة.
-
تحسينات استقرارية عالجت أعطالًا محتملة عند تبديل أنواع المهام (مثل من إعادة التسمية إلى التقسيم)، ما يرفع الاعتمادية في الخطوط التشغيلية الطويلة.
مرونة المخرجات وتجميع النتائج
-
يدعم إخراج CSV وTXT وXLSX لتغذية أنظمة ERP/CRM ومستودعات البيانات مباشرة، مع خيارات تسمية مسارات ومجلدات إخراج تسهّل الفرز الآلي.
-
إمكان الإلحاق Append عند توليد ملفات النتائج يتيح تجميع مخرجات آلاف الملفات في تقارير موحدة قابلة للتحليل الفوري.
قابلية الضبط لحالات استخدام معقدة
-
إعدادات مثل الحساسية لحالة الأحرف Case Sensitive والبحث بالأنماط تضبط الدقة في البيئات متعددة القوالب والتنسيقات ضمن نفس الدُفعة.
-
إعدادات محرك الباركود مثل BarcodeDPI وPdfToImageBpp تمنح تحكمًا أدق لجودة التعرف عند اختلاف دقة المسح أو بنية الملفات.
جاهزية على مستوى الخادم
-
مصمم لخوادم ويندوز مع تراخيص خادم تدعم المعالجة غير التفاعلية عالية الحجم، ما يلبي متطلبات الفرق التشغيلية وقواعد الحوكمة المؤسسية.
-
يعمل بانسجام مع سياسات البنية التحتية المؤسسية، بما في ذلك الجداول الزمنية والمهام المؤتمتة، دون الحاجة إلى أدوات مخصصة معقدة.
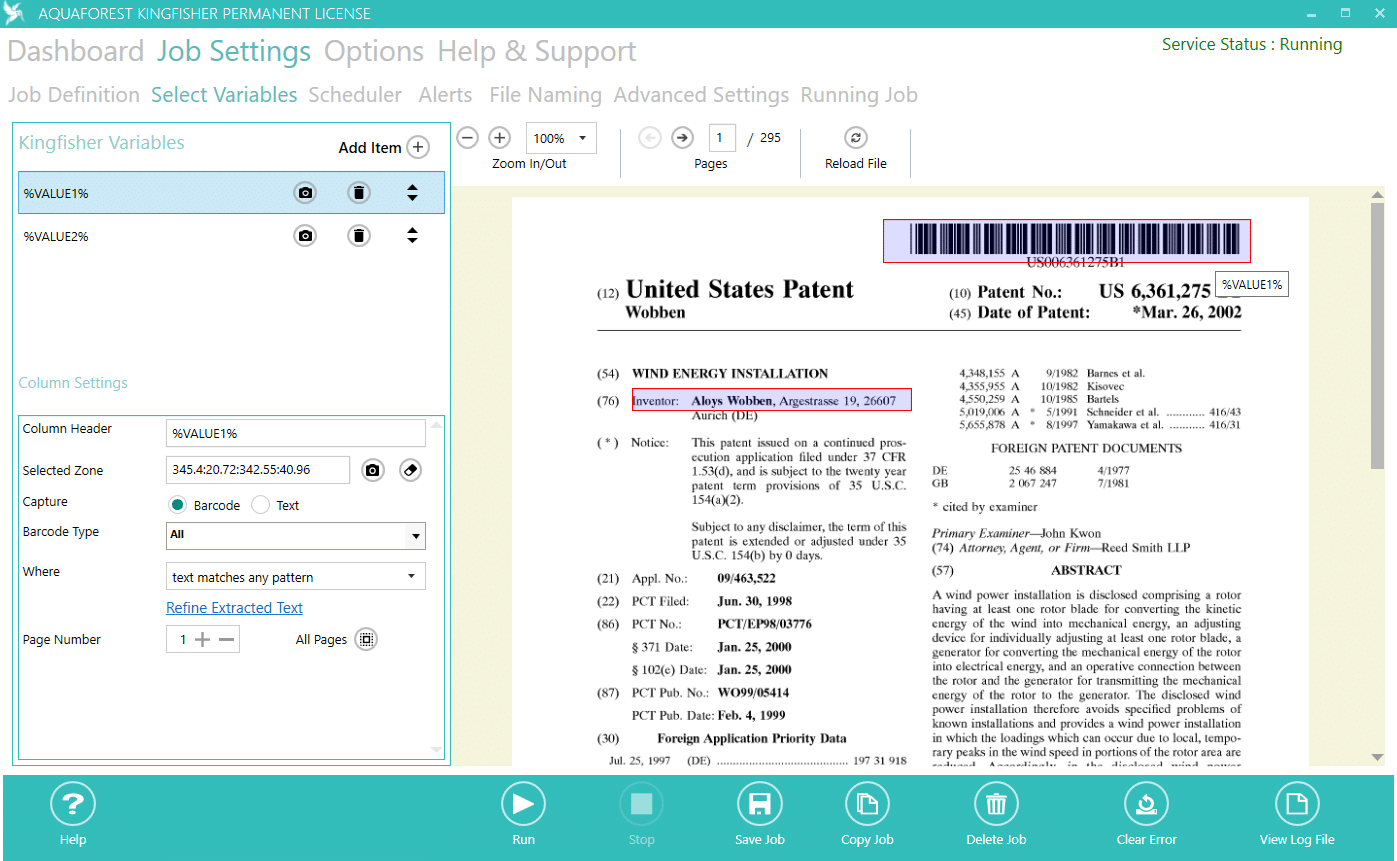
كيف يساعد Kingfisher في تحسين جودة ملفات PDF القابلة للبحث؟
يساعد Aquaforest Kingfisher على رفع جودة ملفات PDF القابلة للبحث عبر دمج OCR لاستخراج النص من الصفحات المصورة وإضافة طبقة نص مخفية تتيح البحث والتطبيق الدقيق للقواعد المبنية على المحتوى داخل نفس سير العمل الجماعي. كما يتيح كشف النص المستهدف بدقة من مناطق محددة Zonal Patterns وربط القيم المستخرجة بعمليات التقسيم وإعادة التسمية والتصدير إلى CSV/Excel، ما يعزز قابلية الفهرسة والاكتشاف في الأنظمة المؤسسية.
جعل النص قابلًا للبحث
-
يستخدم OCR لتحويل ملفات PDF المصورة إلى نص قابل للاستخراج، مما يمكّن محركات البحث المؤسسية من فهرسة المحتوى بدلاً من صور الصفحات غير القابلة للبحث.
-
يدمج القيم الناتجة عن OCR في قواعد المهام مثل إعادة التسمية والتقسيم والاستخراج، لضمان اتساق النتائج عبر مستندات متفاوتة الجودة.
تحسين الدقة عبر المناطق
-
يوفّر Zonal Patterns لتعيين مناطق ثابتة أو نسبية على الصفحة لالتقاط حقول مثل رقم الفاتورة والتاريخ، ما يقلل الضوضاء ويرفع دقة النص القابل للبحث.
-
يدعم تعريف مناطق نصية وباركودية متعددة وإعادة استخدامها كمتغيرات، ما يحسّن الجودة ويضمن ثبات نقاط الالتقاط عبر قوالب المستندات المختلفة.
معالجة الصور والباركود
-
يقرأ الباركودات داخل الصفحة لتقسيم المستندات أو تسميتها، وهو ما يزيل الالتباس بين نسخ متشابهة ويعزّز انتظام الأرشفة القابلة للبحث.
-
الجمع بين النص والباركود في نفس المهمة يرفع الاعتمادية عند تباين جودة المسح أو تخطيط الصفحات، ما ينعكس مباشرة على جودة نتائج البحث.
إخراج بنيوي يعزز الفهرسة
-
يصدّر النص والجداول إلى CSV وTXT وXLSX لتغذية مستودعات البيانات ومحركات الفهرسة ببيانات منظمة، مع خيارات الإلحاق والتجميع لدفعات كبيرة.
-
يسمح بتعيين البيانات الوصفية وخصائص PDF ضمن المهمة، ما يساعد على اتساق معايير الأرشفة وقابلية الاكتشاف بعد المعالجة.
تكامل مع حلول “جعلها قابلة للبحث”
-
يتكامل بسهولة مع منصات الأتمتة مثل Autobahn DX لمعالجة على نطاق ضخم دون كود، بينما تتولى حلول مكملة من نفس العائلة مثل Searchlight تدقيق المستودعات وتحويل الملفات غير القابلة للبحث إلى PDF قابل للبحث عبر طبقة نص مخفية.
-
توفر أدوات Searchlight مراحل تدقيق Audit لتحديد الملفات غير القابلة للبحث وتحويلها ثم مراقبتها دوريًا، ما يضمن استدامة جودة الوثائق القابلة للبحث داخل SharePoint وMicrosoft 365.
شرح آلية عمل برنامج Aquaforest Kingfisher خطوة بخطوة
سنمشي معًا عبر سير عمل نموذجي: إعداد مهمة، تحديد مناطق المحتوى، اختيار عملية (إعادة تسمية/تقسيم/استخراج)، تمكين OCR عند الحاجة، ثم ضبط الإخراج والتشغيل. سأطرح عليك أسئلة بسيطة في كل مرحلة لتتأكد أنك تمسك بالخيط.
1) إنشاء مهمة جديدة (Job)
-
افتح Kingfisher، ثم أنشئ Job جديد وحدد العملية الأساسية من: إعادة تسمية ملفات PDF، تقسيم ملفات PDF، استخراج صفحات، أو استخراج محتوى نصي/جدولي.
-
امنح المهمة اسمًا واضحًا (مثل: “Split_Invoices_Q1”). هذا الاسم يمكن استخدامه كمتغير لاحقًا في القوالب.
-
أسئلة توجيهية: ما الهدف الأساسي لديك الآن؟ هل تريد “تقسيم” أم “إعادة تسمية” أم “استخراج بيانات”؟
2) تهيئة المصادر والمجلدات
-
اختر مجلد الإدخال الذي يحتوي على ملفات PDF، وحدد مجلد الإخراج. فعّل خيار Create Folders لإنشاء المسارات تلقائيًا إن لزم.
-
حدّد سلوك الأخطاء: متابعة عند الخطأ Continue on Error، وخيار Overwrite Existing Files إذا أردت السماح بالاستبدال.
-
سؤال سريع: هل ملفاتك ضمن مجلد واحد أم عدة مجلدات فرعية تحتاج فحصًا تكراريًا؟
3) تعريف العملية بالتفصيل
-
إعادة التسمية Rename:
-
بالاعتماد على نص داخل الصفحة: اختر Rename based on Text Match، وحدد منطقة النص المطلوبة، ويمكنك استخدام تعابير نمطية وكلمات قبل/بعد للتحقق.
-
بالاعتماد على باركود: اختر Rename based on Barcode، ويمكنك انتقاء باركود من منطقة محددة أو استخدام أول باركود يُكتشف.
-
مزيج النص والباركود: Rename based on Text and Barcode لزيادة الاعتمادية.
-
-
التقسيم Split: افصل المستند عند تغيّر نص في منطقة محددة أو عند اكتشاف باركود/إشارة مرجعية، مع دعم تعيين القوالب لأسماء الملفات الناتجة.
-
استخراج الصفحات Extract Pages: حدد نطاقات الصفحات أو قواعد تعتمد على المحتوى ثم احفظها كملفات مستقلة.
-
استخراج المحتوى Extract Content: استخرج نصًا/حقولًا/جداول إلى CSV أو TXT أو XLSX، مفيد للتغذية في ERP/CRM.
-
سؤال تحقق: ما الحقل الذي ستعتمد عليه كمعرّف رئيسي؟ رقم فاتورة من نص المنطقة أم قيمة باركود؟
4) تحديد مناطق الالتقاط (Zonal Patterns)
-
استخدم Zone Definer لاختيار مناطق على الصفحة تُقرأ منها القيم (نص أو باركود) وإسنادها لمتغيرات مثل %VALUE1%، مع إمكان صقل الاستخراج بإعدادات إضافية (مثل نص قبل/بعد).
-
هذه المتغيرات تُعاد استخدامها في التسمية، التقسيم، أو تصدير البيانات، وهي ميزة محورية لاتباع منهج قائم على المحتوى.
-
سؤال قصير: هل موضع الحقل ثابت عبر القوالب أم يتغير بين النماذج؟
5) تفعيل OCR عند الحاجة
-
إذا كانت الملفات صورًا فقط (غير قابلة للبحث)، فعّل High Performance OCR ضمن المهمة ليصبح النص قابلًا للاستخراج والتطابق أثناء التحويل.
-
نصيحة: فعّل OCR فقط عند الحاجة لتقليل زمن التنفيذ على الدُفعات الكبيرة.
-
سؤال: هل تلاحظ أن ملفاتك ممسوحة ضوئيًا أم أنها PDF نصي أصلاً؟
6) بناء قوالب أسماء الملفات ووجهات الإخراج
-
استخدم قوالب تسمية مرنة تتضمن متغيرات جاهزة مثل %FILENAME% و%DATE% و%RUNDATE% و%JOBNAME%، إضافة إلى القيم الملتقطة %VALUE% أو الفهارس %INDEX%.
-
مثال عملي: C:\Output%VALUE%%INDEX%.pdf أو Report%RUNDATE%.xlsx.
-
سؤال: هل تريد دمج أكثر من قيمة في الاسم مثل رقم الفاتورة والتاريخ؟
7) خيارات التعامل مع الملفات غير المطابقة
-
Files With No Match: اختر أحد السلوكيات الثلاثة: عدم النسخ، النسخ فقط، النسخ وإعادة التسمية بقالب بديل.
-
مفيد لضمان عدم ضياع ملفات خارج القواعد، مع إبقائها في مسار مراقَب.
-
سؤال: ماذا تفضل أن يحدث لملفات لا تحتوي على الحقل المطلوب؟
8) الأداء والمعالجة المتوازية
-
فعّل Multi-Core لتسريع الدُفعات الكبيرة وفق الترخيص المتاح، واضبط Max Cores حسب موارد الخادم.
-
جرّب أحجام دفعات صغيرة أولًا لضبط الإعدادات قبل التوسع.
-
سؤال: كم عدد الأنوية المتاحة على خادمك الإنتاجي؟
9) تشغيل المهمة والمراقبة
-
شغّل المهمة من الواجهة أو سطر الأوامر. Kingfisher يحفظ تعريفات المهام XML ويمكن تشغيلها آليًا عبر Command Line في عمليات بدون تدخل بشري.
-
راقب السجلات والملخصات لضبط المناطق أو الأنماط إذا ظهرت حالات عدم تطابق.
-
سؤال: هل تحتاج جدولة ليلية أو تشغيلًا متكاملًا ضمن سكربتات الأتمتة؟
10) التحقق والجودة ثم التوسع
-
افتح عينات من المخرجات للتحقق من الأسماء، التقسيم، ودقة القيم. عدّل Zonal Patterns أو التعابير النمطية حتى تصل لمعدل دقة مستقر.
-
بعد التحقق، طبّق الإعدادات على كامل الأرشيف بثقة.
خلاصة سريعة
-
الفكرة المحورية: “اعتمد على محتوى الصفحة” عبر Zonal Patterns وOCR، ثم طبّق عمليات Rename/Split/Extract بقوالب متغيرات مرنة لضمان نتائج دقيقة وقابلة للأتمتة.
-
تذكّر ضبط سلوك No Match، والقوالب، والمعالجة المتوازية قبل التشغيل واسع النطاق.
تحميل موفق للجميع
انتهى الموضوع
تابع أحدث و أفضل البرامج من قسم البرامج من هنا
كما يمكنك متابعتنا على صفحة فارس الاسطوانات على الفيسبوك
ويمكنك الإنضمام لجروب فارس الإسطوانات على الفيسبوك .
مع تحيات موقع فارس الاسطوانات